搜索到
38
篇与
shilinkun
的结果
-
 muduo源码分析之muduo简单运用 博客网址:www.shicoder.top微信:kj11011029欢迎加群聊天 :452380935今天不先实现muduo项目,我们先来看下muduo库的基本使用,只有了解了如何用,才能在写代码的时候知道自己写的找个函数是干嘛的,实际上是怎么使用的这个函数。首先说简单点,就是定义一个Server,设置两个回调函数// 回调连接相关的事件 void onConnection(const TcpConnectionPtr &conn); // 回调读写事件 void onMessage(const TcpConnectionPtr &conn, Buffer *buffer, Timestamp time);意思就是当有客户连接或者断开连接的时候,需要Server做什么,当连接上有读写事件发生时候,需要Server做什么。比如一个EchoServer,当建立连接的时候,会自动调用onConnection函数,当比如我们发送一个消息时候,会自动调用onMessage函数。还有2个重要函数loop,startserver.start(); loop.loop();这里简答讲下这2个的区别,其实如果和Epoll做对比的话,start就相当于epoll_create,loop就相当于epoll_wait,后面再根据代码具体说明2个的区别。以上就是基本的muduo使用,下一章就开始具体的muduo代码实现。
muduo源码分析之muduo简单运用 博客网址:www.shicoder.top微信:kj11011029欢迎加群聊天 :452380935今天不先实现muduo项目,我们先来看下muduo库的基本使用,只有了解了如何用,才能在写代码的时候知道自己写的找个函数是干嘛的,实际上是怎么使用的这个函数。首先说简单点,就是定义一个Server,设置两个回调函数// 回调连接相关的事件 void onConnection(const TcpConnectionPtr &conn); // 回调读写事件 void onMessage(const TcpConnectionPtr &conn, Buffer *buffer, Timestamp time);意思就是当有客户连接或者断开连接的时候,需要Server做什么,当连接上有读写事件发生时候,需要Server做什么。比如一个EchoServer,当建立连接的时候,会自动调用onConnection函数,当比如我们发送一个消息时候,会自动调用onMessage函数。还有2个重要函数loop,startserver.start(); loop.loop();这里简答讲下这2个的区别,其实如果和Epoll做对比的话,start就相当于epoll_create,loop就相当于epoll_wait,后面再根据代码具体说明2个的区别。以上就是基本的muduo使用,下一章就开始具体的muduo代码实现。 -
-
-
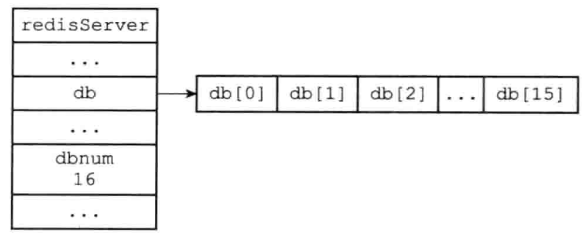
redis数据库 博客网址:www.shicoder.top微信:kj11011029欢迎加群聊天 :452380935这一次主要是接着redis服务器接着进行代码讲解,因为redis服务器中包含大量的数据库,因为redis也对每个数据库设计了结构体redis数据库在上面redisServer中,有一个数组redisDb *db,这个数组中就是存放的是该服务器所有的数据库,redisDb就是数据库字段,redisServer中的dbnum就是该数组的大小 // redis服务器中每一个数据库都是这样一个实例 typedef struct redisDb { // 数据库键空间,保存着数据库中的所有键值对 dict *dict; // 键的过期时间,字典的键为键,字典的值为过期事件 UNIX 时间戳 dict *expires; // 正处于阻塞状态的键 dict *blocking_keys; // 可以解除阻塞的键 dict *ready_keys; // 正在被 WATCH 命令监视的键 dict *watched_keys; struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */ // 数据库号码 int id; // 数据库的键的平均 TTL ,统计信息 long long avg_ttl; } redisDb;过期策略在redisDb中,有一个字段为键的过期时间,因此针对过期的键,redis有一套自己的过期策略,下面进行讲解:定时删除:在设置键过期时间的同时,创建一个定时器惰性删除:每次要用这个键的时候,先检查是否过期定期删除:每隔一段时间,对数据库键进行扫描,删除部分过期键redis是使用惰性删除和定期删除配合实现的过期策略惰性删除代码为db.c/expireIfNeeded,每次执行命令前都执行该函数/* * 检查 key 是否已经过期,如果是的话,将它从数据库中删除。 * * 返回 0 表示键没有过期时间,或者键未过期。 * * 返回 1 表示键已经因为过期而被删除了。 * * 惰性删除 所有读写数据库的命令在执行前都会进行检查 * */ int expireIfNeeded(redisDb *db, robj *key) { // 取出键的过期时间 mstime_t when = getExpire(db,key); mstime_t now; // 没有过期时间 if (when < 0) return 0; // 如果服务器正在进行载入,那么不进行任何过期检查 if (server.loading) return 0; /* If we are in the context of a Lua script, we claim that time is * blocked to when the Lua script started. This way a key can expire * only the first time it is accessed and not in the middle of the * script execution, making propagation to slaves / AOF consistent. * See issue #1525 on Github for more information. */ now = server.lua_caller ? server.lua_time_start : mstime(); // 当服务器运行在 replication 模式时 // 附属节点并不主动删除 key // 它只返回一个逻辑上正确的返回值 // 真正的删除操作要等待主节点发来删除命令时才执行 // 从而保证数据的同步 if (server.masterhost != NULL) return now > when; // 运行到这里,表示键带有过期时间,并且服务器为主节点 // 如果未过期,返回 0 if (now <= when) return 0; /* Delete the key */ server.stat_expiredkeys++; // 向 AOF 文件和附属节点传播过期信息 propagateExpire(db,key); // 发送事件通知 notifyKeyspaceEvent(REDIS_NOTIFY_EXPIRED, "expired",key,db->id); // 将过期键从数据库中删除 return dbDelete(db,key); }定期删除代码为redis.c/activeExpireCycle,每当redis周期性执行redis.c/serverCron时候,就会调用该函数,它在规定的时间内,遍历各个数据库,随机检查一部分键,若过期则删除/* * 函数尝试删除数据库中已经过期的键。 * 当带有过期时间的键比较少时,函数运行得比较保守, * 如果带有过期时间的键比较多,那么函数会以更积极的方式来删除过期键, * 从而可能地释放被过期键占用的内存。 * * * 每次循环中被测试的数据库数目不会超过 REDIS_DBCRON_DBS_PER_CALL 。 * * * 如果 timelimit_exit 为真,那么说明还有更多删除工作要做, * 那么在 beforeSleep() 函数调用时,程序会再次执行这个函数。 * * * 过期循环的类型: * * * 如果循环的类型为 ACTIVE_EXPIRE_CYCLE_FAST , * 那么函数会以“快速过期”模式执行, * 执行的时间不会长过 EXPIRE_FAST_CYCLE_DURATION 毫秒, * 并且在 EXPIRE_FAST_CYCLE_DURATION 毫秒之内不会再重新执行。 * * 如果循环的类型为 ACTIVE_EXPIRE_CYCLE_SLOW , * 那么函数会以“正常过期”模式执行, * 函数的执行时限为 REDIS_HS 常量的一个百分比, * 这个百分比由 REDIS_EXPIRELOOKUPS_TIME_PERC 定义。 * * 定期删除 服务器周期性执行redis.c/serverConn时候会执行该函数 * * 函数执行大概流程: * * 1、函数每次运行时,都从一定数量的数据库中取出一定数量的随机键进行检查,并删除其中的过期键。 * * 2、全局变量current_db会记录当前activeExpireCycle函数检查的进度, * 并在下一次activeExpireCycle函数调用时,接着上一次的进度进行处理。 * 比如说,如果当前activeExpirecycle函数在遍历10号数据库时返回了, * 那么下次activeExpirecycle函数执行时,将从11号数据库开始查找并删除过期键。 * * 3、随着activeExpireCycle函数的不断执行,服务器中的所有数据库都会被检查一遍, * 这时函数将current_db变量重置为0,然后再次开始新一轮的检查工作。 */ void activeExpireCycle(int type) { // 静态变量,用来累积函数连续执行时的数据 // 表明目前检测到哪个数据库了 static unsigned int current_db = 0; static int timelimit_exit = 0; static long long last_fast_cycle = 0; unsigned int j, iteration = 0; // 默认每次处理的数据库数量 unsigned int dbs_per_call = REDIS_DBCRON_DBS_PER_CALL; // 函数开始的时间 long long start = ustime(), timelimit; // 快速模式 if (type == ACTIVE_EXPIRE_CYCLE_FAST) { // 如果上次函数没有触发 timelimit_exit ,那么不执行处理 if (!timelimit_exit) return; // 如果距离上次执行未够一定时间,那么不执行处理 if (start < last_fast_cycle + ACTIVE_EXPIRE_CYCLE_FAST_DURATION*2) return; // 运行到这里,说明执行快速处理,记录当前时间 last_fast_cycle = start; } /* * 一般情况下,函数只处理 REDIS_DBCRON_DBS_PER_CALL 个数据库, * 除非: * * 1) 当前数据库的数量小于 REDIS_DBCRON_DBS_PER_CALL * 2) 如果上次处理遇到了时间上限,那么这次需要对所有数据库进行扫描, * 这可以避免过多的过期键占用空间 */ if (dbs_per_call > server.dbnum || timelimit_exit) dbs_per_call = server.dbnum; /* We can use at max ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC percentage of CPU time * per iteration. Since this function gets called with a frequency of * server.hz times per second, the following is the max amount of * microseconds we can spend in this function. */ // 函数处理的微秒时间上限 // ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 默认为 25 ,也即是 25 % 的 CPU 时间 timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100; timelimit_exit = 0; if (timelimit <= 0) timelimit = 1; // 如果是运行在快速模式之下 // 那么最多只能运行 FAST_DURATION 微秒 // 默认值为 1000 (微秒) if (type == ACTIVE_EXPIRE_CYCLE_FAST) timelimit = ACTIVE_EXPIRE_CYCLE_FAST_DURATION; /* in microseconds. */ // 遍历数据库 for (j = 0; j < dbs_per_call; j++) { int expired; // 指向要处理的数据库 redisDb *db = server.db+(current_db % server.dbnum); // 为 DB 计数器加一,如果进入 do 循环之后因为超时而跳出 // 那么下次会直接从下个 DB 开始处理 current_db++; /* Continue to expire if at the end of the cycle more than 25% * of the keys were expired. */ do { unsigned long num, slots; long long now, ttl_sum; int ttl_samples; // 获取数据库中带过期时间的键的数量 // 如果该数量为 0 ,直接跳过这个数据库 if ((num = dictSize(db->expires)) == 0) { db->avg_ttl = 0; break; } // 获取数据库中键值对的数量 slots = dictSlots(db->expires); // 当前时间 now = mstime(); // 这个数据库的使用率低于 1% ,扫描起来太费力了(大部分都会 MISS) // 跳过,等待字典收缩程序运行 if (num && slots > DICT_HT_INITIAL_SIZE && (num*100/slots < 1)) break; /* The main collection cycle. Sample random keys among keys * with an expire set, checking for expired ones. * * 样本计数器 */ // 已处理过期键计数器 expired = 0; // 键的总 TTL 计数器 ttl_sum = 0; // 总共处理的键计数器 ttl_samples = 0; // 每次最多只能检查 LOOKUPS_PER_LOOP 个键 // 默认每个数据库检查的键数量 if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP) num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP; // 开始遍历数据库 while (num--) { dictEntry *de; long long ttl; // 从 expires 中随机取出一个带过期时间的键 if ((de = dictGetRandomKey(db->expires)) == NULL) break; // 计算 TTL ttl = dictGetSignedIntegerVal(de)-now; // 如果键已经过期,那么删除它,并将 expired 计数器增一 if (activeExpireCycleTryExpire(db,de,now)) expired++; if (ttl < 0) ttl = 0; // 累积键的 TTL ttl_sum += ttl; // 累积处理键的个数 ttl_samples++; } // 为这个数据库更新平均 TTL 统计数据 if (ttl_samples) { // 计算当前平均值 long long avg_ttl = ttl_sum/ttl_samples; // 如果这是第一次设置数据库平均 TTL ,那么进行初始化 if (db->avg_ttl == 0) db->avg_ttl = avg_ttl; // 取数据库的上次平均 TTL 和今次平均 TTL 的平均值 db->avg_ttl = (db->avg_ttl+avg_ttl)/2; } // 更新遍历次数 iteration++; // 每遍历 16 次执行一次 if ((iteration & 0xf) == 0 && (ustime()-start) > timelimit) { // 如果遍历次数正好是 16 的倍数 // 并且遍历的时间超过了 timelimit // 那么断开 timelimit_exit timelimit_exit = 1; } // 已经超时了,返回 if (timelimit_exit) return; // 如果已删除的过期键占当前总数据库带过期时间的键数量的 25 % // 那么不再遍历 } while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4); } }redis客户端因为redis可以和多个客户端进行连接,因此为了区分每个客户端,redis内部为每个连接客户端创建一个结构体redisClient,然后将多个结构体用链表连接在一起typedef struct redisClient { // 套接字描述符 int fd; // 当前正在使用的数据库 使用select可以切换数据库,因为服务器刚开始创建了16个 redisDb *db; // 当前正在使用的数据库的 id (号码) int dictid; // 客户端的名字 robj *name; // 查询缓冲区 sds querybuf; // 查询缓冲区长度峰值 size_t querybuf_peak; // 参数数量 int argc; // 参数对象数组 robj **argv; // 记录被客户端执行的命令 struct redisCommand *cmd, *lastcmd; // 请求的类型:内联命令还是多条命令 int reqtype; // 剩余未读取的命令内容数量 int multibulklen; // 命令内容的长度 long bulklen; // 回复链表 list *reply; // 回复链表中对象的总大小 unsigned long reply_bytes; / // 已发送字节,处理 short write 用 int sentlen; // 创建客户端的时间 time_t ctime; // 客户端最后一次和服务器互动的时间 time_t lastinteraction; // 客户端的输出缓冲区超过软性限制的时间 time_t obuf_soft_limit_reached_time; // 客户端状态标志 int flags; // 当 server.requirepass 不为 NULL 时 // 代表认证的状态 // 0 代表未认证, 1 代表已认证 int authenticated; // 复制状态 int replstate; // 用于保存主服务器传来的 RDB 文件的文件描述符 int repldbfd; // 读取主服务器传来的 RDB 文件的偏移量 off_t repldboff; // 主服务器传来的 RDB 文件的大小 off_t repldbsize; sds replpreamble; // 主服务器的复制偏移量 long long reploff; // 从服务器最后一次发送 REPLCONF ACK 时的偏移量 long long repl_ack_off; // 从服务器最后一次发送 REPLCONF ACK 的时间 long long repl_ack_time; // 主服务器的 master run ID // 保存在客户端,用于执行部分重同步 char replrunid[REDIS_RUN_ID_SIZE+1]; // 从服务器的监听端口号 int slave_listening_port; // 事务状态 multiState mstate; // 阻塞类型 int btype; // 阻塞状态 blockingState bpop; // 最后被写入的全局复制偏移量 long long woff; // 被监视的键 list *watched_keys; // 这个字典记录了客户端所有订阅的频道 // 键为频道名字,值为 NULL // 也即是,一个频道的集合 dict *pubsub_channels; // 链表,包含多个 pubsubPattern 结构 // 记录了所有订阅频道的客户端的信息 // 新 pubsubPattern 结构总是被添加到表尾 list *pubsub_patterns; sds peerid; // 回复偏移量 int bufpos; // 回复缓冲区 char buf[REDIS_REPLY_CHUNK_BYTES]; } redisClient;
-
redis数据结构 博客网址:www.shicoder.top微信:kj11011029欢迎加群聊天 :452380935引言从本次开始,对Redis设计与实现进行阅读及相关读书笔记的记录。Redis版本为3.0数据结构简单动态字符串SDSsds数据结构位于sds.h/sdshdr/* * 保存字符串对象的结构 */ struct sdshdr { // buf 中已占用空间的长度 int len; // buf 中剩余可用空间的长度 int free; // 数据空间 char buf[]; };相对于C语言的字符串,SDS的优点在于常数复杂度获取字符串长度杜绝缓冲区溢出减少修改字符串所带来的内存重新分配(注意,释放空间时候,不会真的释放,而是设置free的值)链表链表的相关代码在adlist.h中链表节点listNode/* * 双端链表节点 */ typedef struct listNode { // 前置节点 struct listNode *prev; // 后置节点 struct listNode *next; // 节点的值 void *value; } listNode;由多个listNode组成的双端链表链表结构list/* * 双端链表结构 */ typedef struct list { // 表头节点 listNode *head; // 表尾节点 listNode *tail; // 节点值复制函数 void *(*dup)(void *ptr); // 节点值释放函数 void (*free)(void *ptr); // 节点值对比函数 int (*match)(void *ptr, void *key); // 链表所包含的节点数量 unsigned long len; } list;字典redis中的字典使用哈希表实现,其代码在dict.h中哈希表结构dictht/* * 哈希表 * * 每个字典都使用两个哈希表,从而实现渐进式 rehash 。 */ typedef struct dictht { // 哈希表数组 dictEntry **table; // 哈希表大小 unsigned long size; // 哈希表大小掩码,用于计算索引值 // 总是等于 size - 1 比如7号,当计算索引时候, 7&sizemask就可以得到 unsigned long sizemask; // 该哈希表已有节点的数量 unsigned long used; } dictht;其中dictEntry为一个键值对/* * 哈希表节点 */ typedef struct dictEntry { // 键 void *key // 值 union { void *val; uint64_t u64; int64_t s64; } v; // 指向下个哈希表节点,形成链表 表明是一个链地址法解决哈希冲突 struct dictEntry *next; } dictEntry;下面为了形象表示一个哈希表,给出一个例子下面给出一个多个dictEntry连接的哈希表最终Redis中的字典数据结构如下/* * 字典 */ typedef struct dict { // 类型特定函数 dictType *type; // 私有数据 void *privdata; // 哈希表 dictht ht[2]; // rehash 索引 // 当 rehash 不在进行时,值为 -1 int rehashidx; /* rehashing not in progress if rehashidx == -1 */ // 目前正在运行的安全迭代器的数量 int iterators; /* number of iterators currently running */ } dict; /* * 字典类型特定函数 */ typedef struct dictType { // 计算哈希值的函数 redis默认的函数算法为murmurhash2 unsigned int (*hashFunction)(const void *key); // 复制键的函数 void *(*keyDup)(void *privdata, const void *key); // 复制值的函数 void *(*valDup)(void *privdata, const void *obj); // 对比键的函数 int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 销毁键的函数 void (*keyDestructor)(void *privdata, void *key); // 销毁值的函数 void (*valDestructor)(void *privdata, void *obj); } dictType;跳跃表redis中的跳跃表结构代码为redis.h/zskiplistNode和redis.h/zskiplist/* ZSETs use a specialized version of Skiplists */ /* * 跳跃表节点 */ typedef struct zskiplistNode { // 成员对象 robj *obj; // 分值 注意redis跳跃表按照节点从小到大排列 double score; // 后退指针 struct zskiplistNode *backward; // 层 数组大小按照幂次定律(越大的数出现概率越小)1-32随机数字 struct zskiplistLevel { // 前进指针 struct zskiplistNode *forward; // 跨度 unsigned int span; } level[]; } zskiplistNode; /* * 跳跃表 */ typedef struct zskiplist { // 表头节点和表尾节点 struct zskiplistNode *header, *tail; // 表中节点的数量 unsigned long length; // 表中层数最大的节点的层数 int level; } zskiplist;下面给出一个简单的跳跃表例子前进指针用于遍历跳跃表,下面的虚线为遍历过程整数集合 intset当一个集合里面只有整数值元素时候,且元素数量不超过REDIS_SET_MAX_INTSET_ENTRIES时候,集合底层采用整数集合#define REDIS_SET_MAX_INTSET_ENTRIES 512 /*集合中元素个数小于该值,set底层使用intset*/redis中整数集合代码位于intset.h/intsettypedef struct intset { // 编码方式 uint32_t encoding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 按照从小到大的顺序,且不重复 int8_t contents[]; } intset;contents数组虽然是int8_t,但是里面存放的数据的真实类型由encoding字段决定升级操作假如往下面的整数集合中append类型为int32的65535,则会发生升级,升级的过程主要包括将每个元素所占空间进行扩充,然后设置encoding,升级完后为降级操作注意整数集合无法进行降级,升级之后,会一直持续该编码压缩列表 ziplist压缩列表其实就是一块连续内存,一个压缩列表包括多个节点(entry),每个entry保存一个字节数组或者整数值。在redis源码中, 压缩列表没有数据结构代码定义,压缩列表是一种通过内存特殊编码方式实现的数据结构。他是通过定义一些基地址,然后使用偏移量来定义ziplist,其中大量使用了宏函数定义/* * ziplist 属性宏 */ // 定位到 ziplist 的 bytes 属性,该属性记录了整个 ziplist 所占用的内存字节数 // 用于取出 bytes 属性的现有值,或者为 bytes 属性赋予新值 #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) // 定位到 ziplist 的 offset 属性,该属性记录了到达表尾节点的偏移量 // 用于取出 offset 属性的现有值,或者为 offset 属性赋予新值 #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) // 定位到 ziplist 的 length 属性,该属性记录了 ziplist 包含的节点数量 // 用于取出 length 属性的现有值,或者为 length 属性赋予新值 #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) // 返回 ziplist 表头的大小 #define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) // 返回指向 ziplist 第一个节点(的起始位置)的指针 #define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE) // 返回指向 ziplist 最后一个节点(的起始位置)的指针 #define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) // 返回指向 ziplist 末端 ZIP_END (的起始位置)的指针 #define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)其中,redis对entry使用了数据结构描述,如下代码ziplist.c/zlentry/* * 保存 ziplist 节点信息的结构 */ typedef struct zlentry { // prevrawlen :前置节点的长度 // prevrawlensize :编码 prevrawlen 所需的字节大小 unsigned int prevrawlensize, prevrawlen; // len :当前节点值的长度 // lensize :编码 len 所需的字节大小 unsigned int lensize, len; // 当前节点 header 的大小 // 等于 prevrawlensize + lensize unsigned int headersize; // 当前节点值所使用的编码类型 unsigned char encoding; // 指向当前节点的指针 unsigned char *p; } zlentry;ziplist的创建/* Create a new empty ziplist. * * 创建并返回一个新的 ziplist * * T = O(1) */ unsigned char *ziplistNew(void) { // ZIPLIST_HEADER_SIZE 是 ziplist 表头的大小 // 1 字节是表末端 ZIP_END 的大小 unsigned int bytes = ZIPLIST_HEADER_SIZE+1; // 为表头和表末端分配空间 unsigned char *zl = zmalloc(bytes); // 初始化表属性 ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE); ZIPLIST_LENGTH(zl) = 0; // 设置表末端 zl[bytes-1] = ZIP_END; return zl; }由于压缩列表主要就是为了节约内存,因此对于不同的数据,其编码方式不一样,前面我们已经知道,entry中主要放字节数组和整数,下表给出两种数据不同长度时候的编码 字节数组编码 整数编码 对象本次首先对Redis的相关数据结构进行介绍。Redis对象主要分为5种:REDIS_STRING、REDIS_LIST、REDIS_HASH、REDIS_SET、REDIS_ZSET。下面首先给出Redis中对对象的代码表示// 对象类型 #define REDIS_STRING 0 #define REDIS_LIST 1 #define REDIS_SET 2 #define REDIS_ZSET 3 #define REDIS_HASH 4#define REDIS_LRU_BITS 24 #define REDIS_LRU_CLOCK_MAX ((1<<REDIS_LRU_BITS)-1) /* Max value of obj->lru */ #define REDIS_LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */ typedef struct redisObject { // 类型 类型说明符 位域名:位域长度 标识type占4个二进制位 因为有可能不需要一个完整的字节 // 1个字节8位 unsigned type:4; // 编码 unsigned encoding:4; // 对象最后一次被访问的时间 unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ // 引用计数 int refcount; // 指向实际值的指针 void *ptr; } robj;首先看到有2个字段,为类型和编码,类型就是redis的5种类型,编码就是这个类型底层是用什么编码方式实现但实际上,Redis的内部并不只是这5种对象,对于上面5种对象,都有几种底层实现方式,下面给出各数据结构底层实现的对应方式REDIS_STRING REDIS_STRING表示redis中的字符串类型,其底层由以下三种实现方式REDIS_ENCODING_INT如果一个字符串对象保存的是整数值,且这个整数值可以用long类型表示,则字符串对象会奖整数值保存在字符串对象的ptr属性中,此时会将ptr的void*转换为long127.0.0.1:6379> set number "1" OK 127.0.0.1:6379> object encoding number "int"REDIS_ENCODING_RAW 如果字符串保存的是一个字符串值,且长度大于32字节,redis的字符串对象就会采用简单动态字符串(SDS)实现127.0.0.1:6379> set longstr "Hello, my name is Shi Linkun, is a programmer who loves code, I hope that each blog can let myself consolidate their knowledge, but also let everyone get a little knowledge, thank you" OK 127.0.0.1:6379> object encoding longstr "raw"这里先不对SDS进行详细简介,后续单独对其进行描述REDIS_ENCODING_EMBSTR如果字符串对象保存的是一个字符串,且长度小于等于32字节,则使用embstr编码实现127.0.0.1:6379> set story "hello my name is shilinkun" OK 127.0.0.1:6379> object encoding story "embstr"注意redis3.0版本中实际间隔为39字节#define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39 robj *createStringObject(char *ptr, size_t len) { if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT) return createEmbeddedStringObject(ptr,len); else return createRawStringObject(ptr,len); }为什么是39字节,这里参考这个知乎的解释embstr是一块连续的内存区域,由redisObject和sdshdr组成。其中redisObject占16个字节,当buf内的字符串长度是39时,sdshdr的大小为8+39+1=48,那一个字节是'\0'。加起来刚好64。是不是发现了什么?typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; void *ptr; } robj; struct sdshdr { unsigned int len; unsigned int free; char buf[]; };从2.4版本开始,redis开始使用jemalloc内存分配器。这个比glibc的malloc要好不少,还省内存。在这里可以简单理解,jemalloc会分配8,16,32,64等字节的内存。embstr最小为16+8+8+1=33,所以最小分配64字节。当字符数小于39时,都会分配64字节。三个编码的转换int->raw向一个保存整数数值的字符串对象使用APPEND命令,就会使得int转变为rawembstr->raw对embstr类型的字符串,执行任何的修改命令,都会变为raw相关命令字符串命令的实现在t_string.c中REDIS_LIST列表对象底层主要由2种编码方式:REDIS_ENCODING_ZIPLIST、REDIS_ENCODING_LINKEDLISTREDIS_ENCODING_ZIPLISTziplist是指使用压缩列表实现REDIS_ENCODING_LINKLISTlinklist是使用双端链表实现编码转换redis.h#define REDIS_LIST_MAX_ZIPLIST_ENTRIES 512 /*list中元素个数小于该值,list底层使用ziplist*/ #define REDIS_LIST_MAX_ZIPLIST_VALUE 64 /*list中所有的字符串长度小于该值,list底层使用ziplist*/上述两个宏定义分别与redis的配置文件中list-max-ziplist-entries和list-max-ziplist-value对应REDIS_HASH哈希对象主要有2种编码方式,REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_HTREDIS_ENCODING_ZIPLISTziplist作为底层实现,先放入键,后放入值REDIS_ENCODING_HT编码转换#define REDIS_HASH_MAX_ZIPLIST_ENTRIES 512 //哈希对象保存的键值对数量小于512个,使用ziplist; #define REDIS_HASH_MAX_ZIPLIST_VALUE 64 //哈希对象保存的所有键值对的键和值的字符串长度都小于64字节,使用ziplist;上述两个宏定义分别与redis的配置文件中hash-max-ziplist-entries和hash-max-ziplist-value对应REDIS_SET集合的底层编码方式也是两种:REDIS_ENCODING_INTSET和REDIS_ENCODING_HTREDIS_ENCODING_INTSET使用该编码方式作为集合的底层实现时候,一般是整数集合,比如REDIS_ENCODING_HT使用哈希表作为集合的底层实现方式时,所有的值作为键,但对应的值为null编码转换#define REDIS_SET_MAX_INTSET_ENTRIES 512 /*集合中元素个数小于该值,且全为整数,set底层使用intset*/对应的redis配置文件选项为set-max-intset-entriesREDIS_ZSET有序集合底层实现为:REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_SKIPLISTREDIS_ENCODING_ZIPLIST当使用压缩列表作为有序集合的底层实现时候,压缩列表的entry有2个值,一个是值,一个是得分,同时按照得分由小到大进行排列REDIS_ENCODING_SKIPLIST当使用跳跃表进行底层实现时候,一个有序集合同时包括:一个跳跃表一个字典为什么有序集合需要同时使用跳跃表和字典来实现?在理论上,有序集合可以单独使用字典或者跳跃表的其中一种数据结构来实现,但无论单独使用字典还是跳跃表,在性能上对比起同时使用字典和跳跃表都会有所降低。举个例子,如果我们只使用字典来实现有序集合,那么虽然以O(1)复杂度查找成员的分值这一特性会被保留,但是,因为字典以无序的方式来保存集合元素,所以每次在执行范围型操作——比如ZRANK、ZRANGE等命令时,程序都需要对字典保存的所有元素进行排序,完成这种排序需要至少O(NlogN)时间复杂度,以及额外的O(N)内存空间(因为要创建一个数组来保存排序后的元素)。另一方面,如果我们只使用跳跃表来实现有序集合,那么跳跃表执行范围型操作的所有优点都会被保留,但因为没有了字典,所以根据成员查找分值这一操作的复杂度将从O(1)上升为O(logN)。因为以上原因,为了让有序集合的查找和范围型操作都尽可能快地执行,Redis 选择了同时使用字典和跳跃表两种数据结构来实现有序集合。编码转换#define REDIS_ZSET_MAX_ZIPLIST_ENTRIES 128 /*有序集合中元素个数小于该值,zset底层使用ziplist*/ #define REDIS_ZSET_MAX_ZIPLIST_VALUE 64 /*有序集合中元素长度小于该值,zset底层使用ziplist*/上述两个宏定义分别与redis的配置文件中zset-max-ziplist-entries和zset-max-ziplist-value对应总结这一次把redis的数据结构和对应的对象实现方式大致说了一遍,最重要的还是什么时候使用什么数据结构,并且各种数据结构一些命令的时间复杂度等,这些其实还没有进行阐述,后面会单独开一章进行讲解,因为在实际项目中,我们要针对不同场景对数据结构进行选取