


博客网址:www.shicoder.top
微信:kj11011029
欢迎加群聊天 :452380935
引言
从本次开始,对Redis设计与实现进行阅读及相关读书笔记的记录。Redis版本为3.0
数据结构
简单动态字符串SDS
sds数据结构位于sds.h/sdshdr
/*
* 保存字符串对象的结构
*/
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char buf[];
};相对于C语言的字符串,SDS的优点在于
- 常数复杂度获取字符串长度
- 杜绝缓冲区溢出
- 减少修改字符串所带来的内存重新分配(注意,释放空间时候,不会真的释放,而是设置free的值)
链表
链表的相关代码在adlist.h中
链表节点listNode
/*
* 双端链表节点
*/
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;由多个listNode组成的双端链表

链表结构list
/*
* 双端链表结构
*/
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
// 链表所包含的节点数量
unsigned long len;
} list;
字典
redis中的字典使用哈希表实现,其代码在dict.h中
哈希表结构dictht
/*
* 哈希表
*
* 每个字典都使用两个哈希表,从而实现渐进式 rehash 。
*/
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1 比如7号,当计算索引时候, 7&sizemask就可以得到
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;其中dictEntry为一个键值对
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表 表明是一个链地址法解决哈希冲突
struct dictEntry *next;
} dictEntry;下面为了形象表示一个哈希表,给出一个例子

下面给出一个多个dictEntry连接的哈希表

最终Redis中的字典数据结构如下
/*
* 字典
*/
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;
/*
* 字典类型特定函数
*/
typedef struct dictType {
// 计算哈希值的函数 redis默认的函数算法为murmurhash2
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;跳跃表
redis中的跳跃表结构代码为redis.h/zskiplistNode和redis.h/zskiplist
/* ZSETs use a specialized version of Skiplists */
/*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值 注意redis跳跃表按照节点从小到大排列
double score;
// 后退指针
struct zskiplistNode *backward;
// 层 数组大小按照幂次定律(越大的数出现概率越小)1-32随机数字
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
/*
* 跳跃表
*/
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;下面给出一个简单的跳跃表例子

前进指针用于遍历跳跃表,下面的虚线为遍历过程

整数集合 intset
当一个集合里面只有整数值元素时候,且元素数量不超过REDIS_SET_MAX_INTSET_ENTRIES时候,集合底层采用整数集合
#define REDIS_SET_MAX_INTSET_ENTRIES 512 /*集合中元素个数小于该值,set底层使用intset*/redis中整数集合代码位于intset.h/intset
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组 按照从小到大的顺序,且不重复
int8_t contents[];
} intset;contents数组虽然是int8_t,但是里面存放的数据的真实类型由encoding字段决定
- 升级操作
假如往下面的整数集合中append类型为int32的65535,则会发生升级,升级的过程主要包括将每个元素所占空间进行扩充,然后设置encoding,升级完后为


- 降级操作
注意整数集合无法进行降级,升级之后,会一直持续该编码
压缩列表 ziplist
压缩列表其实就是一块连续内存,一个压缩列表包括多个节点(entry),每个entry保存一个字节数组或者整数值。在redis源码中, 压缩列表没有数据结构代码定义,压缩列表是一种通过内存特殊编码方式实现的数据结构。他是通过定义一些基地址,然后使用偏移量来定义ziplist,其中大量使用了宏函数定义
/*
* ziplist 属性宏
*/
// 定位到 ziplist 的 bytes 属性,该属性记录了整个 ziplist 所占用的内存字节数
// 用于取出 bytes 属性的现有值,或者为 bytes 属性赋予新值
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
// 定位到 ziplist 的 offset 属性,该属性记录了到达表尾节点的偏移量
// 用于取出 offset 属性的现有值,或者为 offset 属性赋予新值
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
// 定位到 ziplist 的 length 属性,该属性记录了 ziplist 包含的节点数量
// 用于取出 length 属性的现有值,或者为 length 属性赋予新值
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
// 返回 ziplist 表头的大小
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// 返回指向 ziplist 第一个节点(的起始位置)的指针
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
// 返回指向 ziplist 最后一个节点(的起始位置)的指针
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
// 返回指向 ziplist 末端 ZIP_END (的起始位置)的指针
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)

其中,redis对entry使用了数据结构描述,如下代码ziplist.c/zlentry
/*
* 保存 ziplist 节点信息的结构
*/
typedef struct zlentry {
// prevrawlen :前置节点的长度
// prevrawlensize :编码 prevrawlen 所需的字节大小
unsigned int prevrawlensize, prevrawlen;
// len :当前节点值的长度
// lensize :编码 len 所需的字节大小
unsigned int lensize, len;
// 当前节点 header 的大小
// 等于 prevrawlensize + lensize
unsigned int headersize;
// 当前节点值所使用的编码类型
unsigned char encoding;
// 指向当前节点的指针
unsigned char *p;
} zlentry;- ziplist的创建
/* Create a new empty ziplist.
*
* 创建并返回一个新的 ziplist
*
* T = O(1)
*/
unsigned char *ziplistNew(void) {
// ZIPLIST_HEADER_SIZE 是 ziplist 表头的大小
// 1 字节是表末端 ZIP_END 的大小
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
// 为表头和表末端分配空间
unsigned char *zl = zmalloc(bytes);
// 初始化表属性
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
// 设置表末端
zl[bytes-1] = ZIP_END;
return zl;
}由于压缩列表主要就是为了节约内存,因此对于不同的数据,其编码方式不一样,前面我们已经知道,entry中主要放字节数组和整数,下表给出两种数据不同长度时候的编码

字节数组编码
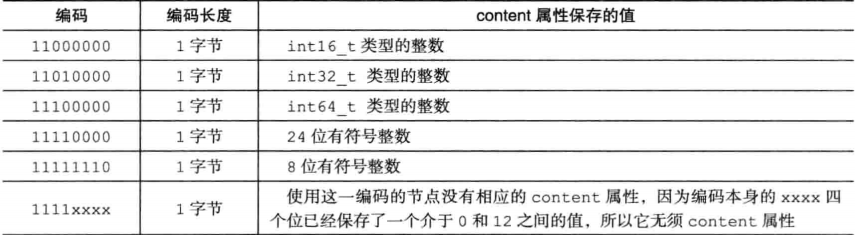
整数编码
对象
本次首先对Redis的相关数据结构进行介绍。Redis对象主要分为5种:REDIS_STRING、REDIS_LIST、REDIS_HASH、REDIS_SET、REDIS_ZSET。下面首先给出Redis中对对象的代码表示
// 对象类型
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4#define REDIS_LRU_BITS 24
#define REDIS_LRU_CLOCK_MAX ((1<<REDIS_LRU_BITS)-1) /* Max value of obj->lru */
#define REDIS_LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
typedef struct redisObject {
// 类型 类型说明符 位域名:位域长度 标识type占4个二进制位 因为有可能不需要一个完整的字节
// 1个字节8位
unsigned type:4;
// 编码
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
// 引用计数
int refcount;
// 指向实际值的指针
void *ptr;
} robj;首先看到有2个字段,为类型和编码,类型就是redis的5种类型,编码就是这个类型底层是用什么编码方式实现

但实际上,Redis的内部并不只是这5种对象,对于上面5种对象,都有几种底层实现方式,下面给出各数据结构底层实现的对应方式
REDIS_STRING
REDIS_STRING表示redis中的字符串类型,其底层由以下三种实现方式

REDIS_ENCODING_INT
如果一个字符串对象保存的是整数值,且这个整数值可以用long类型表示,则字符串对象会奖整数值保存在字符串对象的ptr属性中,此时会将ptr的void*转换为long
127.0.0.1:6379> set number "1"
OK
127.0.0.1:6379> object encoding number
"int"REDIS_ENCODING_RAW
如果字符串保存的是一个字符串值,且长度大于32字节,redis的字符串对象就会采用简单动态字符串(SDS)实现
127.0.0.1:6379> set longstr "Hello, my name is Shi Linkun, is a programmer who loves code, I hope that each blog can let myself consolidate their knowledge, but also let everyone get a little knowledge, thank you"
OK
127.0.0.1:6379> object encoding longstr
"raw"这里先不对SDS进行详细简介,后续单独对其进行描述
REDIS_ENCODING_EMBSTR
如果字符串对象保存的是一个字符串,且长度小于等于32字节,则使用embstr编码实现
127.0.0.1:6379> set story "hello my name is shilinkun"
OK
127.0.0.1:6379> object encoding story
"embstr"注意redis3.0版本中实际间隔为39字节
#define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39
robj *createStringObject(char *ptr, size_t len) {
if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}为什么是39字节,这里参考这个知乎的解释
embstr是一块连续的内存区域,由redisObject和sdshdr组成。其中redisObject占16个字节,当buf内的字符串长度是39时,sdshdr的大小为8+39+1=48,那一个字节是'\0'。加起来刚好64。是不是发现了什么?
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; void *ptr; } robj; struct sdshdr { unsigned int len; unsigned int free; char buf[]; };从2.4版本开始,redis开始使用jemalloc内存分配器。这个比glibc的malloc要好不少,还省内存。在这里可以简单理解,jemalloc会分配8,16,32,64等字节的内存。embstr最小为16+8+8+1=33,所以最小分配64字节。当字符数小于39时,都会分配64字节。
三个编码的转换
int->raw
向一个保存整数数值的字符串对象使用APPEND命令,就会使得int转变为raw
embstr->raw
对embstr类型的字符串,执行任何的修改命令,都会变为raw
相关命令
字符串命令的实现在t_string.c中

REDIS_LIST
列表对象底层主要由2种编码方式:REDIS_ENCODING_ZIPLIST、REDIS_ENCODING_LINKEDLIST

REDIS_ENCODING_ZIPLIST
ziplist是指使用压缩列表实现
REDIS_ENCODING_LINKLIST
linklist是使用双端链表实现
编码转换
redis.h
#define REDIS_LIST_MAX_ZIPLIST_ENTRIES 512 /*list中元素个数小于该值,list底层使用ziplist*/
#define REDIS_LIST_MAX_ZIPLIST_VALUE 64 /*list中所有的字符串长度小于该值,list底层使用ziplist*/上述两个宏定义分别与redis的配置文件中list-max-ziplist-entries和list-max-ziplist-value对应
REDIS_HASH
哈希对象主要有2种编码方式,REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_HT
REDIS_ENCODING_ZIPLIST

ziplist作为底层实现,先放入键,后放入值
REDIS_ENCODING_HT

编码转换
#define REDIS_HASH_MAX_ZIPLIST_ENTRIES 512 //哈希对象保存的键值对数量小于512个,使用ziplist;
#define REDIS_HASH_MAX_ZIPLIST_VALUE 64 //哈希对象保存的所有键值对的键和值的字符串长度都小于64字节,使用ziplist;上述两个宏定义分别与redis的配置文件中hash-max-ziplist-entries和hash-max-ziplist-value对应
REDIS_SET
集合的底层编码方式也是两种:REDIS_ENCODING_INTSET和REDIS_ENCODING_HT
REDIS_ENCODING_INTSET
使用该编码方式作为集合的底层实现时候,一般是整数集合,比如

REDIS_ENCODING_HT
使用哈希表作为集合的底层实现方式时,所有的值作为键,但对应的值为null

编码转换
#define REDIS_SET_MAX_INTSET_ENTRIES 512 /*集合中元素个数小于该值,且全为整数,set底层使用intset*/对应的redis配置文件选项为set-max-intset-entries
REDIS_ZSET
有序集合底层实现为:REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_SKIPLIST
REDIS_ENCODING_ZIPLIST
当使用压缩列表作为有序集合的底层实现时候,压缩列表的entry有2个值,一个是值,一个是得分,同时按照得分由小到大进行排列

REDIS_ENCODING_SKIPLIST
当使用跳跃表进行底层实现时候,一个有序集合同时包括:
- 一个跳跃表
- 一个字典

为什么有序集合需要同时使用跳跃表和字典来实现?
在理论上,有序集合可以单独使用字典或者跳跃表的其中一种数据结构来实现,但无论单独使用字典还是跳跃表,在性能上对比起同时使用字典和跳跃表都会有所降低。举个例子,如果我们只使用字典来实现有序集合,那么虽然以O(1)复杂度查找成员的分值这一特性会被保留,但是,因为字典以无序的方式来保存集合元素,所以每次在执行范围型操作——比如ZRANK、ZRANGE等命令时,程序都需要对字典保存的所有元素进行排序,完成这种排序需要至少O(NlogN)时间复杂度,以及额外的O(N)内存空间(因为要创建一个数组来保存排序后的元素)。
另一方面,如果我们只使用跳跃表来实现有序集合,那么跳跃表执行范围型操作的所有优点都会被保留,但因为没有了字典,所以根据成员查找分值这一操作的复杂度将从O(1)上升为O(logN)。因为以上原因,为了让有序集合的查找和范围型操作都尽可能快地执行,Redis 选择了同时使用字典和跳跃表两种数据结构来实现有序集合。
编码转换
#define REDIS_ZSET_MAX_ZIPLIST_ENTRIES 128 /*有序集合中元素个数小于该值,zset底层使用ziplist*/
#define REDIS_ZSET_MAX_ZIPLIST_VALUE 64 /*有序集合中元素长度小于该值,zset底层使用ziplist*/上述两个宏定义分别与redis的配置文件中zset-max-ziplist-entries和zset-max-ziplist-value对应
总结
这一次把redis的数据结构和对应的对象实现方式大致说了一遍,最重要的还是什么时候使用什么数据结构,并且各种数据结构一些命令的时间复杂度等,这些其实还没有进行阐述,后面会单独开一章进行讲解,因为在实际项目中,我们要针对不同场景对数据结构进行选取
评论 (0)